摘要:
合集:AI案例-深度机器学习-金融
AI问题:时序数据预测
数据集:雅虎财经数据
数据集价值:使用LSTM模型对雅虎股票数据/标普500进行时间序列预测
解决方案:LSTM模型、TensorFlow框架
一、问题描述
股票与金融工具交易是一项利润丰厚的活动。全球各大股票市场促成了此类交易,从而实现了财富的流转。股价时刻波动不休,若能预测其走势,便蕴含着巨大的致富潜力。长期以来,股价预测始终是人们关注的焦点。有效市场假说等理论认为,持续跑赢市场几乎不可能,但也有其他观点对此提出异议。为寻找通往财富的”神奇公式”,既有许多成熟方法,也不断有新研究涌现。传统方法之一是基于时间序列的预测技术;另一种则是基本面分析法——通过剖析大量绩效比率来评估特定股票。在新兴领域,神经网络、遗传算法和集成学习等技术正崭露头角。
股价预测中的另一个挑战是”黑天鹅事件”——这些难以预料的突发事件会引发市场剧烈震荡。此类事件时而发生,具有不可预测性,且往往毫无预警。黑天鹅事件指完全出乎意料且无法预测的重大事件。虽然后果轻微的事件也可能被称为黑天鹅,但该术语通常特指造成重大影响的事件。事后或可对事件成因进行解释,但事前绝无可能预知。在经济体系、金融市场和气象系统等复杂系统中,事件成因往往错综复杂。事后许多解释都难免流于过度简化。
新兴的前沿深度学习模型正在突破股票预测领域的障碍,例如”Transformer与时间嵌入技术”。我们的目标是应用这些新型模型来预测股价。
股票价格预测是指对给定股票未来价值的预估任务。本文基于标普500指数的历史日度收盘价数据,构建并对比不同的预测解决方案。标普500指数由美国经济不同领域的500支股票组成,是美国股市的重要风向标。其他类似指数包括道琼斯30指数、印度NIFTY 50指数、日经225指数等。为便于理解,我们以标普500指数作为研究对象,但其核心概念与方法同样适用于其他个股分析。
本文的任务目标是使用LSTM模型对雅虎股票数据(yahoo_stock.csv)进行时间序列预测,主要预测收盘价(Close)。
二、数据集内容
历史股价信息可公开获取。本次研究中,我们将通过pandas_datareader库调用雅虎财经数据库获取标普500指数历史数据。虽然数据集包含开盘价、调整后收盘价等多维度信息,我们主要采用收盘价/Close数据进行建模。我们编写了通用函数get_raw_data(),将所需信息提取为pandas数据结构。该函数以指数代码作为输入参数(标普500指数代码为GSPC)。以下代码片段演示了如何通过该函数获取所需数据(参见简单LSTM回归案例)。
数据结构
- 股票交易中的最高价/High和最低价/Low指特定时间段内的价格极值。
- 开盘价Open和收盘价Close则分别代表时段起始和结束时的成交价格。
- 成交量Volume反映该时段内的总交易活跃度。
- 调整后价格/Adj Close包含公司行动的影响(如分红、拆股和增发等)。
- 数据时间范围:[2015/11/23, 2020/11/20]
数据样例:yahoo_stock.csv
| Date | High | Low | Open | Close | Volume | Adj Close |
|---|---|---|---|---|---|---|
| 2015/11/23 | 2095.610107421875 | 2081.389892578125 | 2089.409912109375 | 2086.590087890625 | 3587980000 | 2086.590087890625 |
| 2015/11/24 | 2094.1201171875 | 2070.2900390625 | 2084.419922 | 2089.139892578125 | 3884930000 | 2089.139892578125 |
| 2015/11/25 | 2093 | 2086.300048828125 | 2089.300048828125 | 2088.8701171875 | 2852940000 | 2088.8701171875 |
| 2015/11/26 | 2093 | 2086.300048828125 | 2089.300048828125 | 2088.8701171875 | 2852940000 | 2088.8701171875 |
数据集使用许可协议
Deed – CC0 1.0 Universal – Creative Commons
三、LSTM解决方案
1、网络结构
LSTM(Long Short-Term Memory,长短期记忆网络) 是一种特殊的循环神经网络(RNN-Recurrent Neural Network)。它由 Sepp Hochreiter 和 Jürgen Schmidhuber 在 1997 年提出,旨在解决传统 RNN 在处理长序列数据时出现的梯度消失或爆炸问题。简单理解是传统 RNN 的“记忆力”很短,很难记住很久之前的信息。而 LSTM 被设计成具有“长期记忆”能力,能够更好地学习时间序列数据中的长期依赖关系。
LSTM的网络结构图如下所示。图表示包含2个隐含层的LSTM网络,在T=1时刻看,它是一个普通的误差反向传播/BP网络(Error Back Propagation Network),在T=2时刻看也是一个普通的BP网络,只是沿时间轴展开后,T=1训练的隐含层信息中的状态信息会被传递到下一个时刻T=2,如图所示。上图中向右的五个长长的箭头,所的也是隐含层状态在时间轴上的传递。

图:LSTM网络结构
图片引用原文:(8 条消息) LSTM模型结构的可视化 – 知乎
股票价格数据是典型的时间序列数据,即数据点按时间顺序排列。今天的价格不仅受今天新闻的影响,还可能受昨天、上周甚至几个月前趋势和事件的影响。
LSTM 的优势正在于此:
- 记忆能力:它可以记住过去很长一段时间内的重要模式(例如,一个持续的上涨或下跌趋势),并利用这些信息来预测未来的价格。
- 处理序列:它天然地为处理序列数据而设计,非常适合股价这样的连续数据点。
2、门控机制
LSTM 的核心思想是门控机制。LSTM 的关键在于其内部的细胞状态(Cell State) 和三个“门”结构,这些门控机制决定哪些信息应该被记住,哪些应该被遗忘。你可以把细胞状态想象成一个“传送带”,信息可以沿着它一路流动,只有经过“门”的允许才能被添加或移除。
三个门分别是:
- 遗忘门(Forget Gate)作用:决定从细胞状态中丢弃哪些信息。类比:“看到新的数据后,我应该忘记多少过去的旧趋势?”
- 输入门(Input Gate)作用:决定将哪些新信息存入细胞状态。类比:“新的价格数据中,有多少是重要的新信息,需要被记住?”
- 输出门(Output Gate)作用:基于当前的细胞状态,决定输出什么值。类比:“基于我目前记住的所有历史,我现在应该预测一个什么值?”
通过这三个门的协同工作,LSTM 可以有效地学习哪些信息在长期内是重要的,哪些是无关紧要的噪音。
四、处理流程
源码:lstm-stock-price.ipynb
该模型是单变量时间序列预测(Univariate Time Series Forecasting),仅使用历史收盘价/Close来预测未来收盘价,没有使用其他特征(如开盘价、最高价、最低价、成交量等)。
输入输出结构:
- 输入特征数:1(即收盘价)
- 输入维度:
(样本数/n_samples, 时间步长/60天, 特征数/1) - 输出:单个值(下一时间点/第61天的收盘价)
LSTM模型的特征矩阵如下图所示:

图片引用原文:(8 条消息) LSTM模型结构的可视化 – 知乎
1. 主要库导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
numpy:数值计算。pandas:数据处理。matplotlib:可视化。tensorflow:构建和训练LSTM模型。
2. 数据加载与探索
df = pd.read_csv('yahoo_stock.csv')
df.head()
df.shape
df.info()
df.describe()
df.isnull().sum()
- 加载CSV文件,查看前几行、形状、信息、统计描述和缺失值。
- 数据包含1825行,7列,无缺失值。
3. 数据预处理
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
df.sort_index(inplace=True)
- 将
Date列转换为日期时间格式,并设为索引。 - 按日期排序。
4. 探索性数据分析(EDA)
使用matplotlib绘制股票价格走势。包括收盘价、成交量等的时间序列图。
5. 数据标准化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(df['Close'].values.reshape(-1, 1))
将收盘价归一化到0-1之间,便于LSTM训练。
6. 创建时间序列数据集
def create_dataset(data, time_step=60):
X, y = [], []
for i in range(time_step, len(data)):
X.append(data[i-time_step:i, 0])
y.append(data[i, 0])
return np.array(X), np.array(y)
time_step = 60
X, y = create_dataset(scaled_data, time_step)
- 将时间序列数据转换为监督学习格式。
- 需要用过去
N天的数据(时间步长)来预测未来第M天的数据。这里使用前60天的数据预测第61天的收盘价。
7. 构建LSTM模型
model = tf.keras.Sequential([
tf.keras.layers.LSTM(50, return_sequences=True, input_shape=(time_step, 1)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.LSTM(50, return_sequences=False),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
- 使用两个LSTM层,每个层后接Dropout防止过拟合。
- 输出层为Dense层,输出一个值(预测收盘价/Close)。
- 使用Adam优化器和均方误差损失函数。
8. 训练模型
model.fit(X_train, y_train, batch_size=32, epochs=100, validation_data=(X_test, y_test))
使用训练数据训练模型,验证集用于监控过拟合。
9. 预测与反归一化
predictions = model.predict(X_test)
predictions = scaler.inverse_transform(predictions)
对测试集进行预测,并将归一化值转换回原始价格范围。
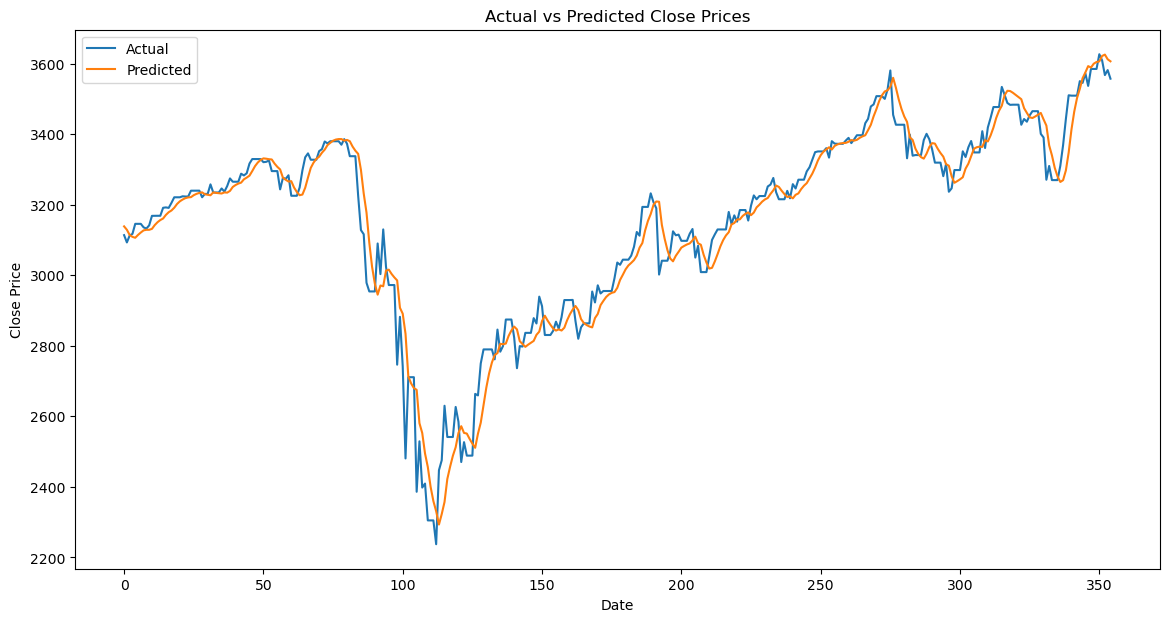
10. 可视化结果
plt.plot(actual_prices, color='black', label='Actual Price')
plt.plot(predictions, color='green', label='Predicted Price')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
绘制实际价格与预测价格的对比图。
11. 模型评估
from sklearn.metrics import mean_squared_error, mean_absolute_error
mse = mean_squared_error(actual_prices, predictions)
mae = mean_absolute_error(actual_prices, predictions)
print(f'MSE: {mse}, MAE: {mae}')
使用均方误差(MSE)和平均绝对误差(MAE)评估模型性能。