摘要:
合集:AI案例-CV-医疗
数据集:科大讯飞2020脑PET图像数据集
数据集价值:利用脑PET图像检测出早期阿尔茨海默综合症病灶
AI问题:图像分类
解决方案:PyTorch框架、EfficientNet模型
一、赛题简介
脑PET全称为脑部正电子发射计算机断层显像(brain positron emission tomography PET),是反映脑部病变的基因、分子、代谢及功能状态的显像。它是利用正电子核素标记葡萄糖等人体代谢物作为显像剂,通过病灶对显像剂的摄取来反映其代谢变化,从而为临床提供疾病的生物代谢信息,为脑癫痫病、脑肿瘤、帕金森病、阿尔茨海默综合症等提供了有效的检测手段。可利用脑PET图像检测出早期阿尔茨海默综合症病灶,并提前介入治疗,从而延缓发病,对后续患者康复治疗有着积极的意义。因此本赛题以阿尔茨海默综合症为例对脑PET图像进行分析与疾病预测。
为研究基于脑PET图像的疾病预测,本次大赛提供了海量脑PET数据集作为脑PET图像检测数据库的训练样本,参赛需根据提供的样本构建模型,对阿尔茨海默综合症进行分析和预测。依据提交的结果文件,采用F1-score指标对参赛的算法性能进行评价。
二、数据集内容
脑PET图像检测数据库,记录了老年人受试志愿者的脑PET影像资料,其中50%被确诊为轻度认知障碍(MCI),25%AD患者,25%健康人,以及跟踪调查受试者信息(包括性别和年龄)。被试按医学诊断分为三类:
CN:健康。特征为:大脑皮层(尤其是外层)呈现出均匀、对称且明亮的颜色(如红色、黄色),表明葡萄糖代谢活跃,神经元功能正常。
AD:阿尔茨海默综合症。特征为:顶叶和颞叶/association cortex 尤其是双侧颞顶叶,代谢显著减低,特定脑区变得暗淡。这是AD最经典、最易识别的特征。
MCI:轻度认知障碍。特征为:图像看起来不像CN那么明亮均匀,也不像AD那样出现大范围的显著暗淡。
数据集中的阿尔茨海默综合症训练图片样例:
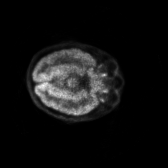
数据集分为全量数据版dataset10000和开发版dataset,不同版本的图片个数不一样。训练和测试数据分别存储在以AD、CN、MCI为名字的文件目录下。
| 分类 | 全量版 | 开发版 |
|---|---|---|
| 训练集CN分类 | 3000 | 1000 |
| 训练集AD分类 | 3000 | 1000 |
| 训练集MCI分类 | 4000 | 0 |
| 测试集 | 2000 | 1000 |
数据集版权许可协议
Deed – CC0 1.0 通用 – Creative Commons
三、解决方案
1、EfficientNet模型
EfficientNet 是2019年由 Google Research 提出的一个深度卷积神经网络架构,设计时侧重于高效性。与传统的卷积神经网络相比,EfficientNet 在相同计算预算下,提供了更高的精度。它使用了一种新的结构化搜索方法,结合了 深度、宽度 和 分辨率 的平衡,通过对这些因素进行系统性调整,达到了更高的效率。
EfficientNet 的核心思想是通过 复合缩放(compound scaling)来同时优化模型的三个重要因素:
- 深度(Depth):网络的层数。
- 宽度(Width):每层的神经元个数。
- 输入分辨率(Resolution):输入图像的分辨率。
ResNet等传统的方法通常分别优化这三个因素,而 EfficientNet 通过复合缩放方法,在一个统一的框架内同时调整它们,找到最优的比例,使得在同样计算量(FLOPs)下获得更高的准确度。这就像盖大楼:
- 传统方法:要么只增加楼层数(深度),要么只增加每层的房间数(宽度),要么只扩大地基面积(分辨率)。这种单一维度的扩展效率很低,容易不稳定。
- EfficientNet方法:根据科学原则,同时规划应该盖多少层、每层多少房间、地基多大,让三者达到最佳平衡。这样盖出来的大楼(模型)既稳固(易于训练)又高效(性能好)。
EfficientNet 从 B0 到 B7 有不同的配置:
- 输入分辨率越来越高
- B0 接收 224×224 的图片。
- B7 接收 600×600 的图片。
- 更高的分辨率意味着图片包含更多的细节信息,模型能看清更细微的特征,从而有助于做出更准确的判断。但计算成本会呈平方级增长。
- 网络越来越宽/深
- 虽然论文没有直接公布每个模型的具体层数和通道数,但根据缩放公式,随着 φ 增大,网络的深度(层数) 和宽度(通道数) 都会增加。
- 更深:模型能够学习更复杂、更抽象的特征组合。
- 更宽:每层能捕获更多种类的特征。
- 参数量和计算量急剧增加
- 从 B0 到 B7,参数量增加了 12倍 以上。
- 计算量增加了近 100倍。
- 这意味着训练和推理所需的内存、时间和计算资源也大幅增加。
- 预测精度稳步提升
- 精度从 B0 的 77.1% 提升到了 B7 的 84.3%,提升了超过 7个百分点。
- 这种提升是饱和的,越往后,为了提升一点点精度,需要付出的计算代价越大(B6到B7只提升了0.3%,但FLOPs几乎翻倍)。
2、安装开发包
选择合适的CUDA版本进行安装,例如pytorch==2.4.1,并安装efficientnet-pytorch:
conda create -n pytorch241-gpu python=3.10
conda activate pytorch241-gpu
conda install pytorch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 pytorch-cuda=12.1 -c pytorch -c nvidia
conda install -c conda-forge efficientnet-pytorch
请参考文章《安装深度学习框架PyTorch》。
3、加载开发包
import torch.optim as optim
import numpy as np
from efficientnet_pytorch import EfficientNet
import time
import config
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
4、配置
config.py
import argparse
parser = argparse.ArgumentParser(description='PET Challenge')
# data in/out and dataset
parser.add_argument('--dataset_train_path', default='./dataset-enhancement/train/*/*.png',
help='train root path')
parser.add_argument('--dataset_test_path', default='./dataset-enhancement/test/AD&CN&MCI',
help='test root path')
# parser.add_argument("--save_dir", default='v0920_b8', help="all data dir") # 运行产生的所有文件保存在此文件夹下
parser.add_argument("--save_dir", default='output', help="all data dir")
parser.add_argument('--v', type=str, default='v0',
help='version')
# 图像增强
Random_Rotation = 30 # 原有 180 可能过于强烈,导致图像变形严重,模型难以学习有效特征。
Color_Jitter = 0.3 # 原有 0.5
parser.add_argument('--ColorJitter', type=float, default=Color_Jitter,
help='transforms.ColorJitter')
parser.add_argument('--RandomRotation', type=int, default=Random_Rotation,
help='transforms.RandomRotation')
parser.add_argument('--Resize', type=int, default=224,
help='transforms.Resize')
# train
TRAIN_IMAGE_NUM = 3000 # 文件夹中总共3000个文件
BATCH_SIZE = 16
K_FOLD = 5 # 若 20 计算成本高
parser.add_argument('--batch_size', type=list, default=BATCH_SIZE,
help='batch size of trainset')
parser.add_argument('--k', type=int, default= K_FOLD,
help='Cross-validation')
EPOCH_NUM = 10 # 测试。。。
MODEL_NAME = 'efficientnet-b0'
LEARNING_RATE = 0.001 # 0.01 高学习率可能导致训练不稳定或难以收敛。
parser.add_argument('--epochs', type=int, default=EPOCH_NUM,
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=LEARNING_RATE,
help='learning rate (default: 0.01)')
parser.add_argument('--gamma', type=float, default=0.5,
help='gamma')
parser.add_argument('--step_size', type=int, default=4,
help='step_size')
# resume 中断训练后恢复训练
parser.add_argument('--resume', type=bool, default=False,
help='resume')
parser.add_argument('--start_epoch', type=int, default=0,
help='start_epoch')
args = parser.parse_args()
四、工作流程
1、数据处理
这段代码定义了一个名为QRDataset的类,该类继承自PyTorch的Dataset类,用于处理图像数据集。这个类主要用于处理二维码图像数据集,并对图像进行预处理。
源码:train.py
class QRDataset(Dataset):
def __init__(self, train_jpg, transform=None):
self.train_jpg = train_jpg
if transform is not None:
self.transform = transform
else:
self.transform = None
# 直接打开图像并返回,不进行任何裁剪
def crop_1(self, img_path):
img = Image.open(img_path).convert('RGB')
return np.array(img)
设置源数据集工作目录:dataset,数据处理后文件目录:dataset-enhancement。
dataset_train_path = './dataset-enhancement/train/*/*.png'
2、创建模型
这段代码定义了一个名为 DogeNet 的 PyTorch 神经网络模型类,DogeNet 类通过以下步骤创建了一个基于 EfficientNet-B8 的神经网络:
- 从 EfficientNet-B8 模型加载预定义架构(但没有加载预训练权重)。
- 将最后的全连接层(
_fc)替换为一个新的输出层,输出类别数为 3(适应三分类问题)。 - 在
forward方法中定义前向传播过程。
这个模型适用于需要使用 EfficientNet-B8 特征提取能力,并且最终需要进行三分类任务的情况。
源码:1_train.py
# 训练(微调)场景下的模型:
# 你的任务与 ImageNet 类似(例如医学图像分类、物体检测等)。
# 你的数据集较小(例如只有几千张脑 PET 图像)。
class DogeNet(nn.Module):
def __init__(self):
super(DogeNet, self).__init__()
# model = EfficientNet.from_pretrained('efficientnet-b5', weights_path='./model/efficientnet-b5-b6417697.pth')
# 推荐使用预训练参数(迁移学习) 自动下载结构和ImageNet权重
model = EfficientNet.from_pretrained(config.MODEL_NAME)
# 替换最后一层,输出3类
in_channel = model._fc.in_features
model._fc = nn.Linear(in_channel, 3)
self.efficientnet = model
def forward(self, img):
out = self.efficientnet(img)
return out
3、模型训练
这段代码定义了一个名为train的函数,用于训练深度学习模型。它接受以下参数:
train_loader: 一个PyTorch DataLoader对象,用于加载训练数据。model: 要训练的深度学习模型。criterion: 损失函数,用于计算模型预测与真实标签之间的差异。optimizer: 优化器,用于更新模型参数以最小化损失函数。epoch: 当前的训练轮次。
函数内部定义了一些用于度量和记录训练过程的变量,如batch_time(每个批次的时间)、losses(损失值)、top1(Top-1准确率)和top5(Top-5准确率)。然后,将模型设置为训练模式,并开始训练循环。在每次迭代中,首先将输入数据和目标标签移动到GPU上(如果可用)。然后计算模型的输出,并使用损失函数计算损失值。接下来,计算预测的Top-1和Top-5准确率,并更新相应的度量变量。之后,使用优化器计算梯度并更新模型参数。最后,记录每个批次的时间。
在训练循环中,每隔100个批次,使用progress.pr2int(i)打印当前批次的索引。训练结束后,返回整个训练轮次的平均损失值。
这个函数可以用于训练各种深度学习模型,只需根据具体任务调整损失函数、优化器和数据加载器即可。
def train(train_loader, model, criterion, optimizer, epoch):
batch_time = AverageMeter('Time', ':6.3f')
# data_time = AverageMeter('Data', ':6.3f')
losses = AverageMeter('Loss', ':.4')
top1 = AverageMeter('Acc@1', ':6.2f')
top5 = AverageMeter('Acc@5', ':6.2f')
progress = ProgressMeter(len(train_loader), batch_time, losses, top1)
# switch to train mode
model.train()
end = time.time()
epoch_loss = []
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
# loss = criterion(output, target)
loss = CrossEntropyLoss_label_smooth(output, target, num_classes=3) # 加2
# '''warm up module'''
# if epoch<warm_epoch:
# warm_up=min(1.0,warm_up+0.9/warm_iteration)
# loss*=warm_up
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 3))
losses.update(loss.item(), input.size(0))
epoch_loss.append(loss.item())
top1.update(acc1[0], input.size(0))
top5.update(acc5[0], input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 100 == 0:
progress.pr2int(i)
return np.mean(epoch_loss)
4、执行训练
训练数据集工作路径:dataset-enhancement
if __name__ == '__main__':
args = config.args
logging = write_log(args.save_dir)
print('K={}\tepochs={}\tbatch_size={}\tresume={}\tlr={}'.format(args.k,
args.epochs, args.batch_size, args.resume, args.lr))
logging.info('K-Fold={}\tepochs={}\tbatch_size={}\tresume={}\tlr={}'.format(args.k,
args.epochs, args.batch_size, args.resume,
args.lr))
k_logger = SummaryWriter('./picture/k/tensorboard/' + args.v) # 记录每k折的loss和acc曲线图
dataset_train_path = './dataset-enhancement/train/*/*.png'
train_jpg = np.array(glob.glob(dataset_train_path))
# 或者如果你想随机选择 X 个文件,可以使用:
train_jpg = np.random.choice(train_jpg, config.TRAIN_IMAGE_NUM, replace=False)
#...
执行:python 1_train.py 。可发现损失函数值在逐步下降。
整体配置信息
- K_Fold/Epoch[0/5 0/10] 表示:使用5折交叉验证、总共训练10个epoch。
- batch_size=16: 每个批次16个样本。训练集合中包括3000个图片文件,总共150个批次。
- resume=False: 不从检查点恢复训练
- lr=0.01: 学习率为0.01
- use_gpu True: 使用GPU进行训练
K=5 epochs=10 batch_size=16 resume=False lr=0.001
use_gpu True
Loaded pretrained weights for efficientnet-b0
epoch=0
K_Fold/Epoch[0/5 0/10]:
[ 0/150] Time 81.314 (81.314) Loss 1.112 (1.112) Acc@1 37.50 ( 37.50)
[ 1/150] Time 0.992 (41.153) Loss 1.091 (1.102) Acc@1 43.75 ( 40.62)
[ 2/150] Time 3.701 (28.669) Loss 1.057 (1.087) Acc@1 56.25 ( 45.83)
[ 3/150] Time 4.149 (22.539) Loss 1.114 (1.094) Acc@1 25.00 ( 40.62)
[ 4/150] Time 4.026 (18.836) Loss 1.083 (1.091) Acc@1 50.00 ( 42.50)
[ 5/150] Time 3.732 (16.319) Loss 1.072 (1.088) Acc@1 50.00 ( 43.75)
[ 6/150] Time 3.974 (14.555) Loss 1.015 (1.078) Acc@1 75.00 ( 48.21)
...
* Acc@1 55.167 Acc@5 100.000
best_acc is :55.16666793823242, lr:0.0005
epoch=6
K_Fold/Epoch[0/5 6/10]:
...
* Acc@1 64.167 Acc@5 100.000
best_acc is :64.16667175292969, lr:0.0005
epoch=7
K_Fold/Epoch[0/5 7/10]:
...
* Acc@1 64.500 Acc@5 100.000
best_acc is :67.16667175292969, lr:0.00025
epoch=8
K_Fold/Epoch[0/5 8/10]:
...
* Acc@1 64.500 Acc@5 100.000
best_acc is :67.16667175292969, lr:0.00025
epoch=9
K_Fold/Epoch[0/5 9/10]:
[146/150] Time 6.207 ( 6.089) Loss 0.8255 (0.8685) Acc@1 62.50 ( 62.41)
[147/150] Time 6.179 ( 6.090) Loss 0.8604 (0.8684) Acc@1 87.50 ( 62.58)
[148/150] Time 5.688 ( 6.087) Loss 1.065 (0.8697) Acc@1 43.75 ( 62.46)
[149/150] Time 5.760 ( 6.085) Loss 0.8894 (0.8699) Acc@1 56.25 ( 62.42)
* Acc@1 66.500 Acc@5 100.000
best_acc is :67.16667175292969, lr:0.00025
加载最好的模型
epoch=0
K_Fold/Epoch[1/5 0/10]:
...
输出:output/best_acc_dogenetv0.pth 权重参数文件。
5、预测
基于训练后的模型,已知一图片进行类别预测:
源码:2_predict.py
预测使用的模型和训练使用的模型一样:
# 推理场景下的模型
class DogeNet(nn.Module):
def __init__(self):
super(DogeNet, self).__init__()
# 重新创建模型结构(必须和训练时一致)
model = EfficientNet.from_name(config.MODEL_NAME) # 不加载预训练参数
in_channel = model._fc.in_features
model._fc = nn.Linear(in_channel, 3)
self.efficientnet = model
def forward(self, img):
out = self.efficientnet(img)
return out
预测:
def predict(test_loader, model, tta=10):
# switch to evaluate mode
model.eval()
test_pred_tta = None
for _ in range(tta):
test_pred = []
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(test_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
output = output.data.cpu().numpy()
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
use_gpu = torch.cuda.is_available()
model = DogeNet().cuda()
# 加载权重参数文件。
model.load_state_dict(torch.load(args.save_dir + '/' + model_path))
if test_pred is None:
test_pred = predict(test_loader, model, 5)
else:
test_pred += predict(test_loader, model, 5)
预测输出文件 best_acc_dogenet.csv
uuid label
1 AD
2 AD
...
源码开源协议
来源:wangying1586