合集:机器学习之强化学习
一、深度Q学习
深度Q学习(即深度动作价值学习)之所以出名,很大程度上是因为它在 2013 年由 DeepMind 提出,并在 2015 年登上《Nature》封面——它仅凭输入屏幕像素和游戏分数,就在 49 款 Atari 游戏中达到了人类甚至超人类的水平。Atari 游戏画面由一个个像素组成,并且通常每一帧都包含了完整的游戏状态信息(例如,玩家的位置、敌人的位置、分数、生命值等)。深度Q学习的成功开启了深度强化学习的时代。总的来说,深度 Q 学习通过神经网络赋予了传统 Q 学习处理复杂问题的能力。
强化学习(Reinforcement-Learning)是一个机器学习领域,它关注的核心问题是:智能体(Agent)如何通过与环境的互动/试错,学习到最优策略,从而获得最大的累积奖励?传统的Q学习(Q-Learning)是一种基于质量/价值Q的强化学习,其核心是计算Q值。而深度强化学习(Deep Reinforcement Learning)是强化学习的一个子领域,它指的是使用深度神经网络来解决强化学习问题。
深度Q学习,即深度动作价值学习(Deep Q-Learning,简称 DQN)是一种将深度学习与强化学习相结合的革命性算法。字母 Q 代表的是 Quality(质量/价值)。这个命名非常直观地反映了它的核心功能:衡量在某个状态下,执行某个特定动作的“质量”或“优劣程度”。具体来说,它通常指代的是动作价值函数,数学上通常写作: Q(s,a) 这个函数的含义是:在状态s下采取动作a,并且在之后都按照最优策略行事,所能够获得的累积奖励的预期。这个 Q 值(质量分数)的高低,直接决定了智能体是否会选择这个动作。
- 高 Q 值 = 高质量的动作 = 预期未来获得的累积奖励越多。
- 低 Q 值 = 低质量的动作 = 预期未来获得的累积奖励越少。
无论是传统的 Q Learning(Q 学习),还是深度 Q 网络(DQN),它们的目标都是一致的:尽可能准确地估计这个“Q 值”。DQN 只是用深度神经网络这个工具,来估算原本难以计算的 Q 值而已。简单来说,DQN解决了传统 Q 学习在面对复杂问题时“记不住”或“算不过来”的困境。
二、交通灯配时优化预测
交通信号控制技术的发展史,是随着城市交通需求的增长和技术手段的进步而不断发展的过程。最早的交通信号控制主要以固定配时为主,该种方法主要是根据对某个交叉口的历史交通流量进行统计后,提前确定一套或多套固定信号周期、信号相序、绿信比等信号控制参数,并在一天中不同的时段进行切换(如早高峰、晚高峰、平峰),其优点是简单、稳定、成本低,但是其静态的特性不能满足交通流实时变化的需求,经常出现绿灯空放或红灯排队的现象,资源利用率极低。为了克服这个缺点,感应控制技术就产生了,感应控制就是利用在交叉口进口道设置环形线圈、微波或者视频检测器,感应控制可以实时检测车辆到达,并且根据预先设定的逻辑动态调整绿灯时长或者跳过没有车流的相位,从而在一定程度上提高了信号配时的灵活性和针对性。
三、模型设计
1、交通相位设计
本系统工作场景为单个交叉路口的交通信号控制。采用的框架为:基于深度神经网络的强化学习模型进行训练和预测。环境为一个 4 路交叉口,每个方向有 4 条进入车道和 4 条驶出车道。每个方向道路长 750 米。每条进入车道定义了车辆可以行驶的可能方向:最左侧车道专用于左转;最右侧车道专用于右转和直行;中间两条车道仅用于直行。交通信号灯系统的布局如下:最左侧车道有专用的交通信号灯,而其他三条车道共享同一个交通信号灯。下图为交通相位图,4个相位对应于增强学习中的4个动作,依次为:
- NSG相位:表示南北方向的车辆可以直行和右转,不允许左转,且东西方向车辆不允许通行;
- NSLG相位:表示南北方向的车辆可以左转和右转,不允许直行,且东西方向车辆不允许通行;
- EWG相位:表示东西方向的车辆可以直行和右转,不允许左转,且南北方向车辆不允许通行;
- EWLG相位:表示东西方向的车辆可以左转和右转,不允许直行,且南北方向车辆不允许通行。
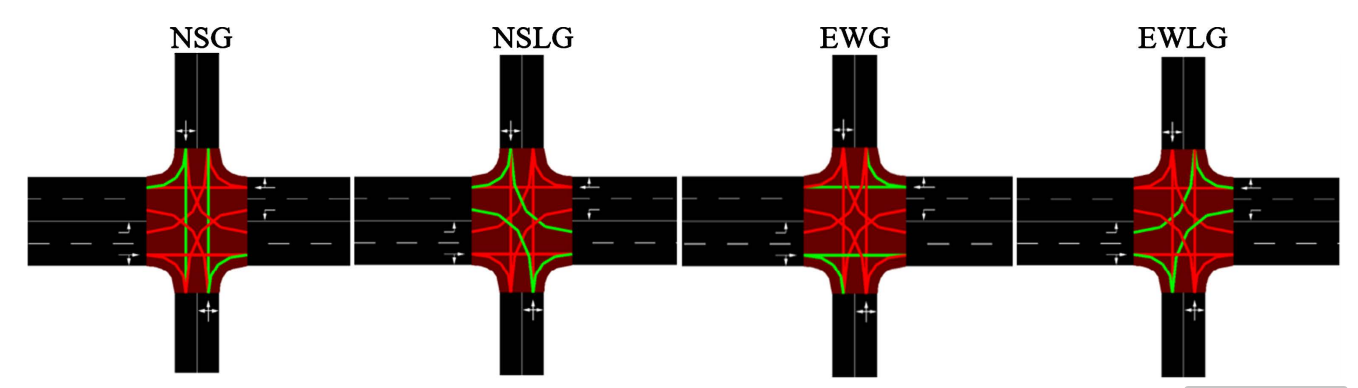
图:交通相位
交通信号相位设计的核心原则是保障交叉口运行安全。相位配置需遵循以下核心安全规则:1)首先,东西方向的直行或左转与南北方向的直行或左转车流会形成直接交叉冲突,因此“东西直行/左转”与“南北直行/左转””相位必须互斥。2)其次,在同方向不同相位间存在特定限制,虽然直行与左转车辆同向行驶,但它们的路径在路口中心会与对向车流相交。因此当启用某方向直行相位时,对向的左转相位必须保持红灯状态;反之当启用左转相位时,对向的直行相位也必须设为红灯。3)此外,相位序列中的黄灯时间设置是重要的安全措施,在相位切换时设置的4秒黄灯期间,实际上包含了清空交叉口所需的全红时间,这确保了当前相位车辆完全通过冲突区域后,再启动下一个可能存在冲突的相位。
交通信号相位变更的决策频率设计为每14秒 (10秒绿灯 + 4秒黄灯) 或 10秒 (相位不变) 做一次决策。
2、十字路口交通状态设计
十字路口交通状态设计为:将进入车道离散化为存在单元,这些单元标识车道内至少有一辆车的存在与否。每个方向有 20 个单元。其中 10 个沿最左侧车道放置,另外 10 个放在其他三条车道上。整个交叉口有 80 个单元。按车道功能进行差异化感知:每个进口道有20个单元格。10个单元格专门布置在最左侧的左转专用车道上,另外10个单元格 布置在剩下的三条车道(通常是直行和右转车道)上。以计算机理论的方式描述十字路口的交通状态,一个标准的十字路口有4个进口道(北、东、南、西)。每个进口道有20个单元格。因此,整个路口的状态就是一个长度为 4 进口道 * 20 单元格 = 80 的二进制向量。最终的状态向量看起来可能是这样的:[0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, … , 1, 0] (共80位)。这个向量就是智能体在每个决策时刻看到的“世界”。
3、深度神经网络模型设计
深度神经网络模型设计为:输入层有 80 个神经元(状态)/num_states,4 个隐藏层/num_layers,每层有 400 个神经元/width_layers。输出层有 4 个神经元,代表 4 个可能的动作/num_actions。这意味着对于每个输入状态,基于该神经网络的预测会输出4个值,每个值对应一个动作的 Q 值。
配置文件:training_settings.ini
[model]
num_layers = 4
width_layers = 400
batch_size = 100
learning_rate = 0.001
training_epochs = 800
[agent]
num_states = 80 # 对应于 _input_dim
num_actions = 4 # 对应于 _output_dim
模型设计的关键代码如下:
from tensorflow.keras import layers
class TrainModel:
def _build_model(self, num_layers, width):
# 输入层
inputs = tf.keras.Input(shape=(self._input_dim,))
x = layers.Dense(width, activation='relu')(inputs)
# 隐藏层
for _ in range(num_layers):
x = layers.Dense(width, activation='relu')(x)
# 输出层
outputs = layers.Dense(self._output_dim, activation='linear')(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs, name='my_model')
model.compile(loss=losses.mean_squared_error, optimizer=Adam(learning_rate=self._learning_rate))
return model
在模型的训练策略上,在系统层面预留了很多细致的设置。损失函数选用了均方误差(Mean Squared Error,MSE),因为MSE对于预测误差比较敏感,可以很好地度量预测值和真实值之间的差距,是一种常用的回归任务损失函数。优化器选择Adam(Adaptive Moment Estimation),Adam是一种自适应学习率的优化算法,它综合了Momentum和RMSprop的优点,在训练过程中可以动态地调整每个参数的学习率,具有收敛快、性能稳定的特点,初始学习率为0.001。 模型训练利用小批量梯度下降法,设置批次数batchsize=100。每个训练周期epoch中,模型遍历所有训练数据集,寻找最佳训练轮次并降低过拟合的手段采用早停法,即在训练时不断观察模型在验证集上的表现(以MSE为准则),如果在连续多个周期验证集中损失不再递减时就停止训练,并且保持最佳表现的模型作为预测使用的模型,整个训练轮次最多为200轮。如此一来,就能令预测模型尽可能掌握交通数据的内在规律,并给出准确率高的预测性能。
4、交通过程车流数据
模拟交通过程生成的方式为:在每个新的交通过程/episode开始时,创建例如1000 辆汽车,你不仅需要决定它们要去哪里(直行或左/右转),还需要决定它们什么时候出现在路口的入口处。生成的车辆中 75% 将直行,25% 将左转或右转。可以利用威布尔/weibull分布生成 1000 个随机数,代表每辆车相对于第一辆车的到达时间间隔,从而模拟真实的随机车流。总仿真时长设计为5400秒(1.5小时)。
源码:generator.py
class TrafficGenerator:
def __init__(self, max_steps, n_cars_generated):
self._n_cars_generated = n_cars_generated # how many cars per episode
self._max_steps = max_steps
def generate_routefile(self, seed):
# Generation of the route of every car for one episode
np.random.seed(seed) # make tests reproducible
# the generation of cars is distributed according to a weibull distribution
timings = np.random.weibull(2, self._n_cars_generated)
timings = np.sort(timings)
# ...
TrafficGen = TrafficGenerator(
config['max_steps'], # 总仿真时长 = 5400秒 = 90分钟 = 1.5小时
config['n_cars_generated'] # 1000
)
5、奖励机制设计
奖励机制设计为:对于一强化学习中的动作选择,奖励值设计为车辆累积等待时间的变化量。车辆累积等待时间减少给予正奖励,否则给予负奖励。目标设计为最小化负奖励 (逼近0)。其中汽车的等待时间是指交通过程模拟自生成以来速度=0所花费的秒数;累积意味着统计4个入口道路车道上每辆车的等待时间。当一辆车离开进入车道(即穿过交叉路口)时,其等待时间不再被计算。
奖励值的计算仅在每个动作执行后计算 ,也就是在每10或14秒一次相位变更时候。只累积负奖励 (惩罚)值,目标为最小化负奖励,使其逼近0。
old_total_wait: 旧时刻的所有车辆等待时间总和
current_total_wait: 新时刻的所有车辆等待时间总和
奖励值/reward = old_total_wait - current_total_wait
差值来源:
├─ 离开路口的车辆: 减少等待时间 → 正奖励
├─ 新到达的车辆: 增加等待时间 → 负奖励
└─ 停止的车辆: 增加等待时间 → 负奖励
6、交通过程仿真
对于一个交通过程/episode的仿真执行流程如下:
源码:training_simulation.py
while step < 5400 (仿真步数循环/5400秒)
1. 获取当前状态 (80维状态向量): _get_state()
2. 计算奖励 (等待时间变化量):reward = old_total_wait - current_total_wait
3. 存储经验到Memory:Memory.add_sample((s, a, r, s'))
4. 选择动作 (epsilon-greedy) :action = _choose_action(state, epsilon)
5. 黄灯切换 (如果相位改变) :_set_yellow_phase() + _simulate(4秒)
6. 绿灯执行:_set_green_phase() + _simulate(10秒)
7. 更新状态变量
保存一个交通过程模拟的统计信息。
时间流程示意:
时间轴 (5400秒 = 90分钟)
│
├─ 0秒: 仿真开始, 第一批车辆生成
├─ 10秒: 第1次决策 (绿灯10秒)
├─ 14秒: 第2次决策 (黄灯4秒 + 绿灯10秒)
├─ 24秒: 第3次决策
│ ...
├─ 5400秒: 仿真结束
四、Q值学习更新和模型训练
1、Q值学习更新原理
当完成一个交通过程/episode的仿真执行流程后,系统从记忆库中随机抽取一批历史经验,用这些经验来更新神经网络的参数,让网络学会更好地估计Q值。这个 _replay 函数是 DQN 算法中最核心的部分,它实现了经验回放和Q值学习更新。深度Q学习网络/DQN的更新原理图解如下:
当前状态 → 网络 → Q(s, a1), Q(s, a2), Q(s, a3), Q(s, a4)
↓
只更新被选动作的Q值
↓
新值 = 奖励 + γ * max Q(s', a')
↓
保留其他动作的Q值不变
这个函数在每个训练轮次(training_epochs = 800)中被反复调用,让网络逐步收敛到最优Q函数。具体实现的源码如下:training_simulation.py
print("Training...")
for _ in range(self._training_epochs): # 每个episode结束后,对神经网络进行训练的轮数(800)
self._replay()
源码:training_simulation.py
def _replay(self):
"""
Retrieve a group of samples from the memory and for each of them update the learning equation, then train
"""
batch = self._Memory.get_samples(self._Model.batch_size)
if len(batch) > 0: # if the memory is full enough
states = np.array([val[0] for val in batch]) # extract states from the batch
next_states = np.array([val[3] for val in batch]) # extract next states from the batch
# prediction
q_s_a = self._Model.predict_batch(states) # predict Q(state), for every sample
q_s_a_d = self._Model.predict_batch(next_states) # predict Q(next_state), for every sample
# setup training arrays
x = np.zeros((len(batch), self._num_states))
y = np.zeros((len(batch), self._num_actions))
for i, b in enumerate(batch):
state, action, reward, _ = b[0], b[1], b[2], b[3] # extract data from one sample
current_q = q_s_a[i] # get the Q(state) predicted before
current_q[action] = reward + self._gamma * np.amax(q_s_a_d[i]) # update Q(state, action)
x[i] = state
y[i] = current_q # Q(state) that includes the updated action value
self._Model.train_batch(x, y) # train the Nerual Network
2、具体工作流程
a. 从记忆库中采样
从经验回放记忆库中随机抽取一批样本。批大小由模型的 batch_size 属性决定(配置中是100),随机采样的目的是打破经验之间的相关性,使训练更稳定。
batch = self._Memory.get_samples(self._Model.batch_size)
b. 提取状态和下一状态
记忆库中的一个样本其格式为:(state, action, reward, next_state)。使用Python列表推导式(List Comprehension),对于每个元素/样本 val,val[0]为取其索引为0的值,也就是样本的当前状态。val[3]为执行动作后的下一个状态。
states = np.array([val[0] for val in batch]) # 提取状态
next_states = np.array([val[3] for val in batch]) # 提取下一状态
c. 批量预测Q值
一次性预测整个批次的所有Q值,比逐个预测效率高得多。q_s_a[i] 是一个数组,包含状态 i 下所有动作的Q值。q_s_a_d[i] 类似,但针对是下一个状态。其中states.shape = (100, 80)表示该批次中包括100个输入状态,每个状态包括80维数据,输出的q_s_a.shape = (100, 4) 。Q 函数定义为:在状态s下,执行每个可能动作a所能获得的期望累积奖励。对于状态s,我们需要知道所有动作的Q值,而不仅仅是已执行动作的Q值。
q_s_a = self._Model.predict_batch(states) # 预测当前状态的Q值
q_s_a_d = self._Model.predict_batch(next_states) # 预测下一状态的Q值
d. Q值学习更新
初始化训练数据:
x = np.zeros((len(batch), self._num_states)) # 神经网络的输入状态
y = np.zeros((len(batch), self._num_actions)) # 目标:期望的4个动作输出(更新后的Q值)
Q值学习更新:
for i, b in enumerate(batch):
state, action, reward, _ = b[0], b[1], b[2], b[3]
current_q = q_s_a[i] # 当前预测的Q值
current_q[action] = reward + self._gamma * np.amax(q_s_a_d[i]) # Q学习更新公式
x[i] = state
y[i] = current_q
这一行是最关键的:
current_q[action] = reward + self._gamma * np.amax(q_s_a_d[i])
这是贝尔曼最优方程的实现:
- reward: 执行动作后获得的即时奖励。
- gamma: 折扣因子(配置中
gamma = 0.75),表示未来奖励的重要性。 - np.amax(q_s_a_d[i]): 使用amax()函数,获取下一状态中最大的Q值,也就是最优未来动作的价值。
- reward + gamma * max_future_q: 这就是目标Q值。
- 我们需要保留其他动作对应的Q值不变,只更新被选中动作/action的Q值,这就要求我们必须知道所有动作的原始Q值。
e. 训练神经网络
训练神经网络的方法为:将状态 x 作为输入,期望输出 y 作为目标。通过梯度下降调整神经网络中的参数,使预测值接近目标值。损失函数采用均方误差(MSE)。
self._Model.train_batch(x, y)
3、模型训练结果展示
python training_main.py
----- Episode 1 of 40
Simulating...
Total reward: -22597.0 - Epsilon: 1.0
Training...
Simulation time: 4.6 s - Training time: 0.0 s - Total: 4.6 s
New best model saved with reward: -22597.0
----- Episode 2 of 40
Simulating...
Total reward: -30588.0 - Epsilon: 0.97
Training...
Simulation time: 14.5 s - Training time: 397.2 s - Total: 411.7 s
----- Episode 3 of 40
Simulating...
Total reward: -27103.0 - Epsilon: 0.95
Training...
Simulation time: 7.9 s - Training time: 391.8 s - Total: 399.7 s
...
----- Episode 40 of 40
Simulating...
Total reward: -4869.0 - Epsilon: 0.03
Training...
Simulation time: 65.1 s - Training time: 402.6 s - Total: 467.7 s
----- Start time: 2025-10-28 18:03:05.946400
----- End time: 2025-10-28 22:48:08.808130
----- Session info saved at: D:\Prj\Order\2510\Traffic-Lamp\Deep-QLearning-Agent-for-Traffic-Signal-Control-master\TLCS\models\model_1\
训练结束后,结果将存储在 “./model/model_x/” 中,其中 x是一个从 1 开始自动生成的递增整数。结果将包括一些图表、用于创建图表的数据、训练好的神经网络文件trained_model.h5,以及代理设置的 ini 文件副本。
4、模型训练报表
延时/等待数据:
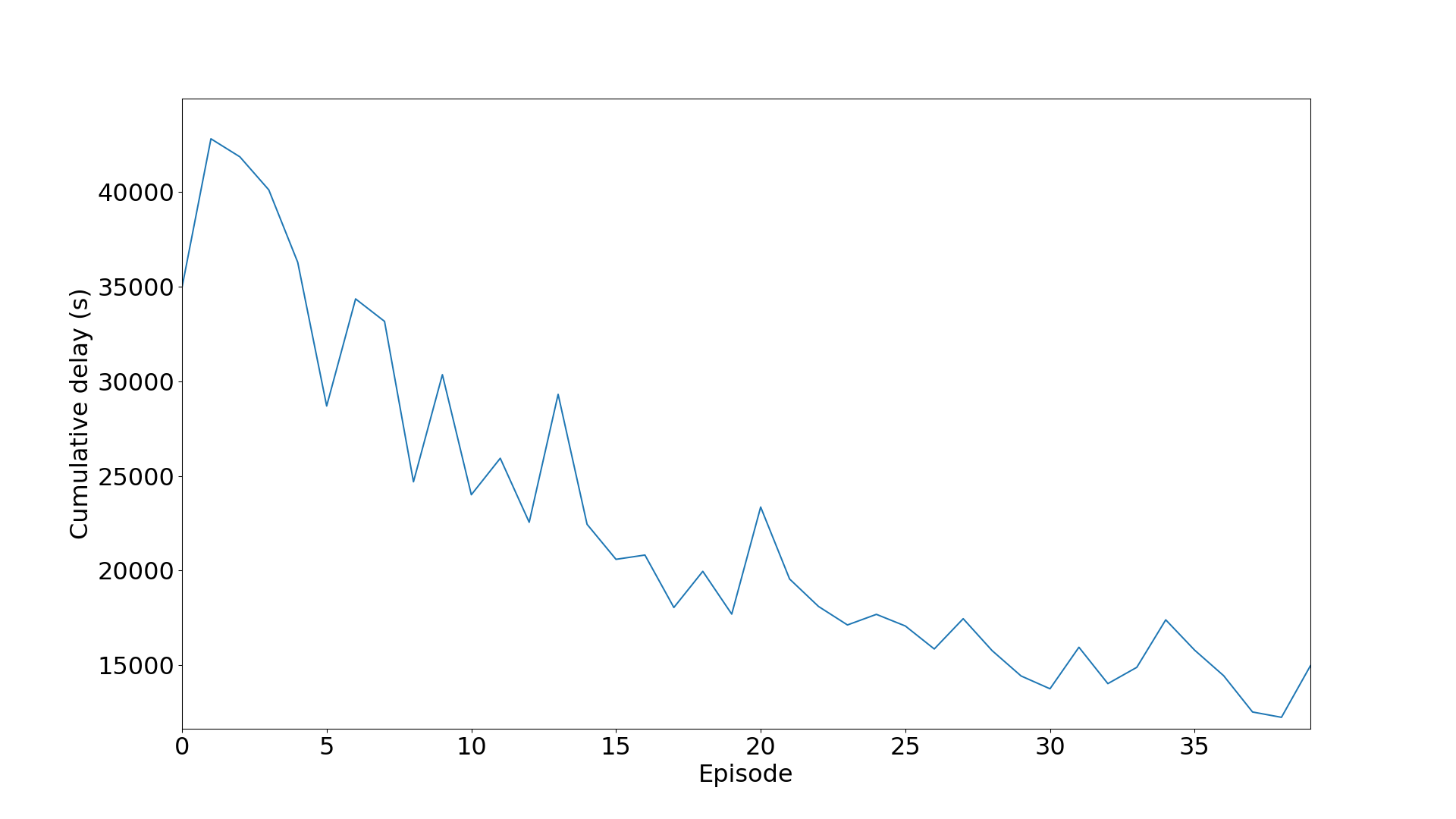
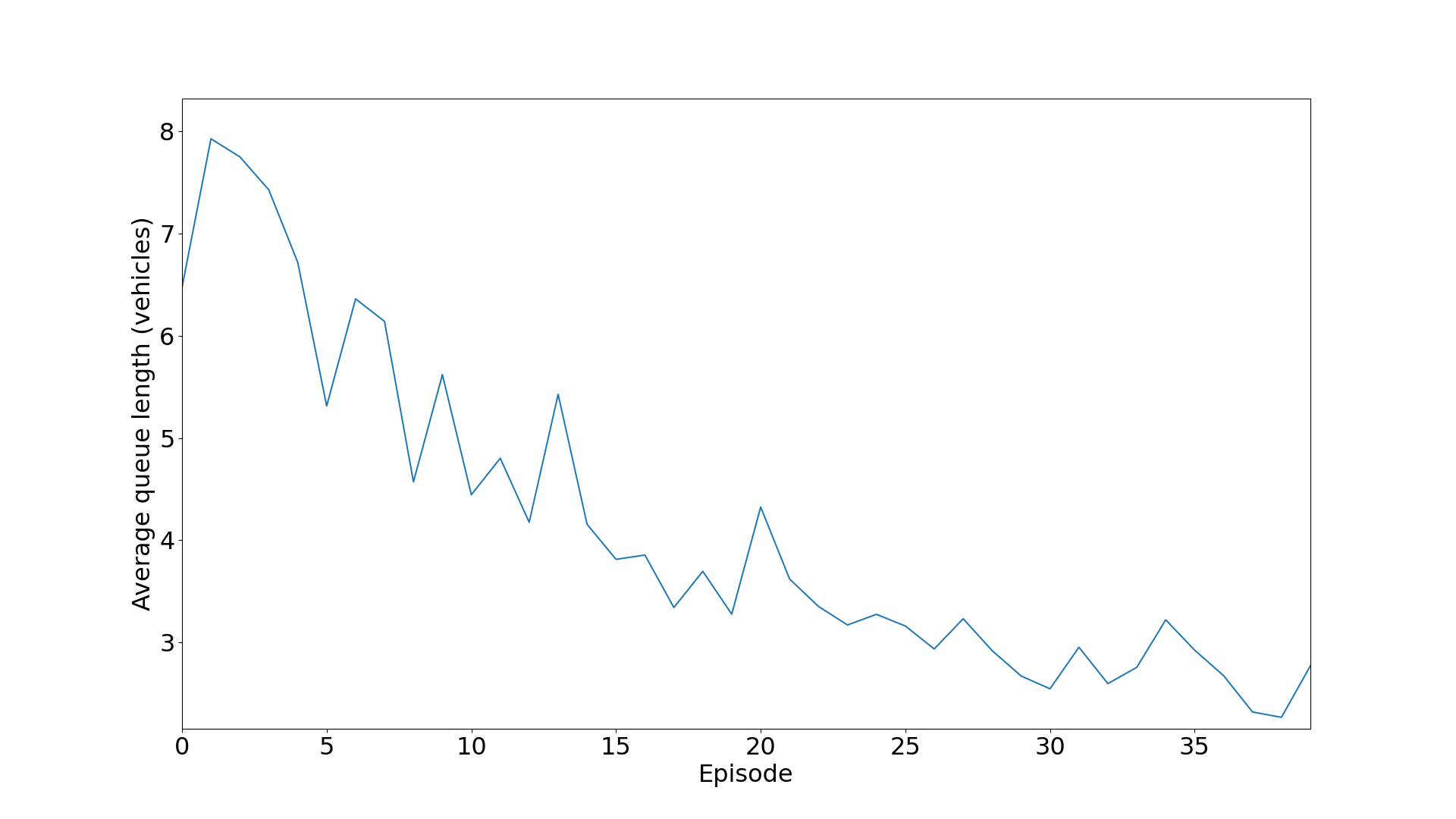
平均等待队列长度/车辆数:
增强学习中的奖励数据:
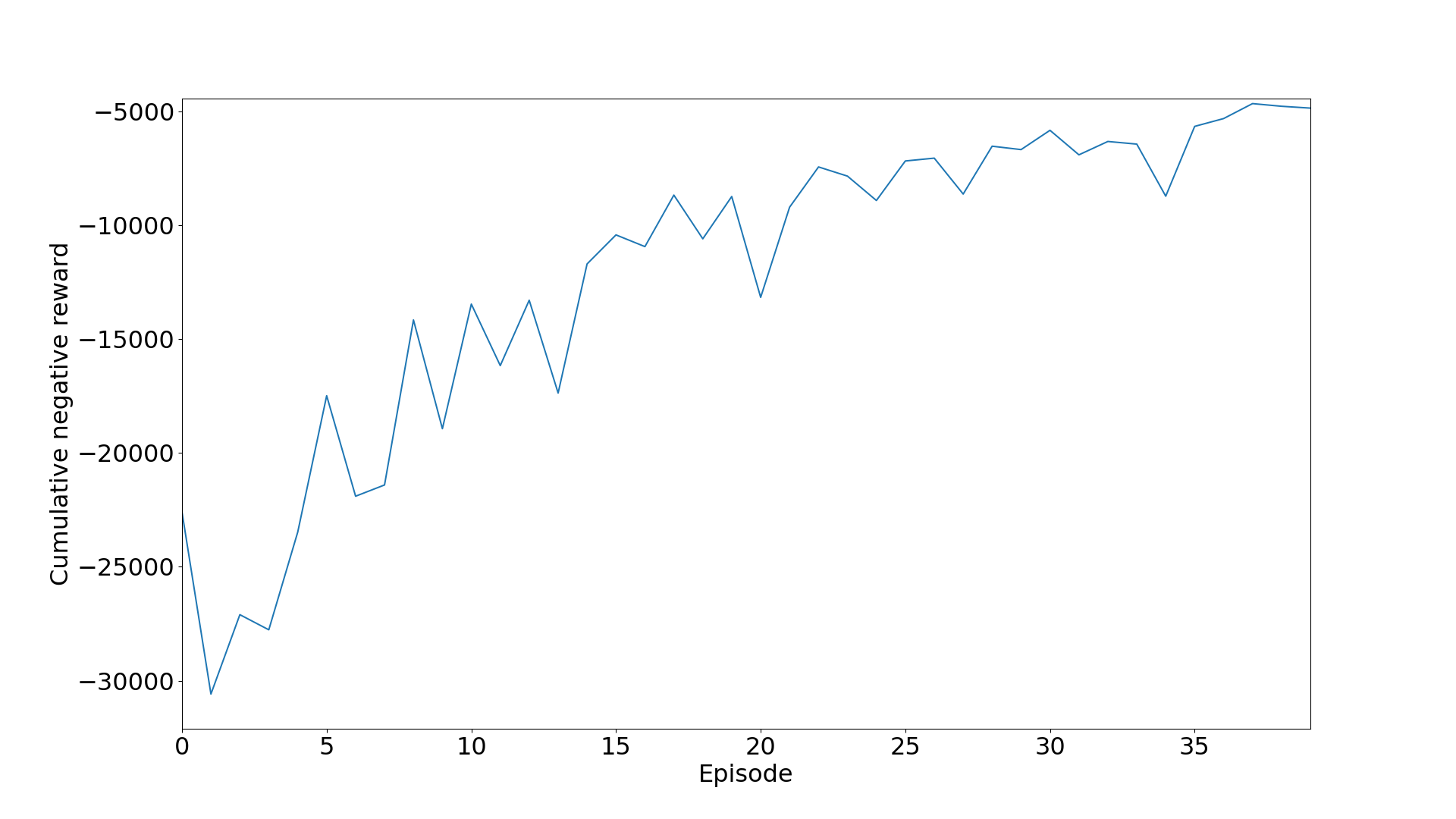
五、模型预测
1、模型预测值的使用
在实际使用训练好的深度Q学习网络模型时,处理这4个预测值的核心原则是:选择 Q 值最大的那个动作执行。这对应了强化学习中”利用(Exploitation)”的思想——既然模型告诉我每个动作的长期价值,那我就选最值钱的。模型的使用方式可以概括为:状态s输入模型->得到4个Q值->挑选最大Q值对应的索引->执行索引对应的交通灯相位。
# testing_simulation.py 中的 _choose_action 方法
def _choose_action(self, state):
# Pick the best action known based on the current state of the env
return np.argmax(self._Model.predict_one(state))
2、模型预测结果展示
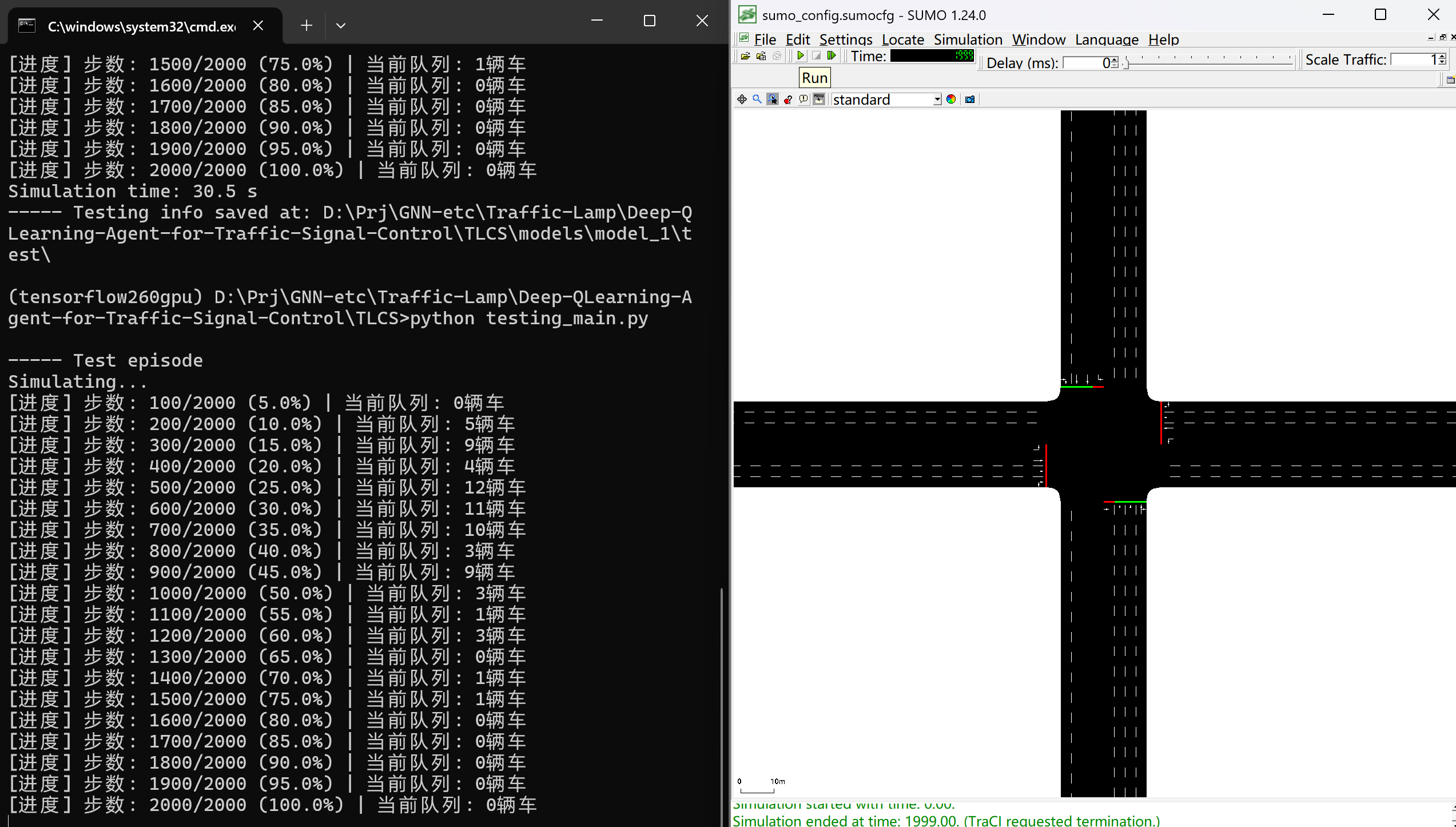
现在您终于可以测试训练好的模型了。测试涉及单次模拟情节,测试结果将存储在 “./model/model_x/test/” 中,其中 x是您指定要测试的模型编号。测试期间使用并包含在文件 testing_settings.ini 中的设置如下(其中一些必须与相应训练中使用的设置相同):
[simulation]
gui = False # 关闭图形界面,不查看仿真结果
max_steps = 2000 # 减少测试步数,快速验证
n_cars_generated = 500 # 减少车辆数,降低负载
运行:
python testing_main.py
----- Test episode
Simulating...
[进度] 步数: 100/2000 (5.0%) | 当前队列: 0辆车
[进度] 步数: 200/2000 (10.0%) | 当前队列: 5辆车
[进度] 步数: 300/2000 (15.0%) | 当前队列: 9辆车
[进度] 步数: 400/2000 (20.0%) | 当前队列: 4辆车
[进度] 步数: 500/2000 (25.0%) | 当前队列: 12辆车
[进度] 步数: 600/2000 (30.0%) | 当前队列: 11辆车
[进度] 步数: 700/2000 (35.0%) | 当前队列: 10辆车
[进度] 步数: 800/2000 (40.0%) | 当前队列: 3辆车
[进度] 步数: 900/2000 (45.0%) | 当前队列: 9辆车
[进度] 步数: 1000/2000 (50.0%) | 当前队列: 3辆车
[进度] 步数: 1100/2000 (55.0%) | 当前队列: 1辆车
[进度] 步数: 1200/2000 (60.0%) | 当前队列: 3辆车
[进度] 步数: 1300/2000 (65.0%) | 当前队列: 0辆车
[进度] 步数: 1400/2000 (70.0%) | 当前队列: 1辆车
[进度] 步数: 1500/2000 (75.0%) | 当前队列: 1辆车
[进度] 步数: 1600/2000 (80.0%) | 当前队列: 0辆车
[进度] 步数: 1700/2000 (85.0%) | 当前队列: 0辆车
[进度] 步数: 1800/2000 (90.0%) | 当前队列: 0辆车
[进度] 步数: 1900/2000 (95.0%) | 当前队列: 0辆车
[进度] 步数: 2000/2000 (100.0%) | 当前队列: 0辆车
Simulation time: 29.8 s
----- Testing info saved at: D:\Prj\Order\2510\Traffic-Lamp\Deep-QLearning-Agent-for-Traffic-Signal-Control-master\TLCS\models\model_1\test\
3、模型预测报表
等待车辆数预测展示:
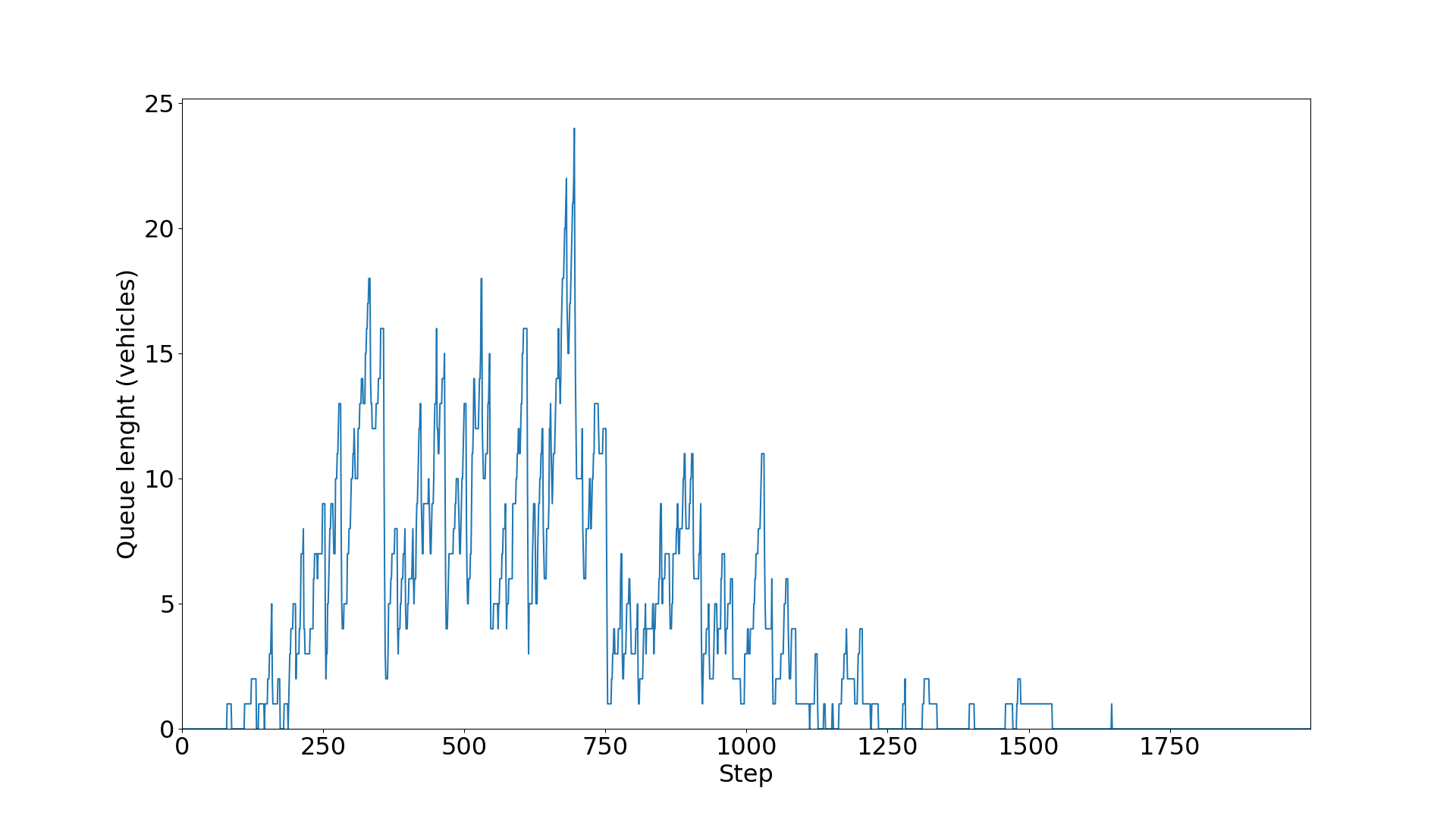
仿真运行图: